论文笔记 | Benchmarking Differential Privacy and Federated Learning for BERT Models
本文最后更新于:2021年9月22日 下午
Benchmarking Differential Privacy and Federated Learning for BERT Models 论文笔记
作者团队:MIT & CMU(Rakshit Naidu) 等
日期:2021.6.26 原文PDF链接
摘要:
通过NLP技术使用一个人的话语集合可用于帮助诊断抑郁症等医疗状况。由于此类数据的敏感性,需要采取隐私措施来处理和训练具有此类数据的模型。在这项工作中,作者在集中式和分布式(联邦学习(FL))设置下研究差分隐私(DP)应用在训练上下文语言模型(BERT、ALBERT、RoBERTa 和 DistilBERT)的影响,并提供有关如何隐私(privately)训练 NLP 模型以及哪些架构和设置提供更理想的隐私效用权衡的见解。作者打算将这项工作用于未来的医疗保健和心理健康研究以保持病史的私密性,因此提供了这项工作的开源实现
实验:
基于BERT模型及其三个变种在不同数据分布下做集中式和分布式的差分隐私和联邦学习的实验,有四种实验设置:集中式传统训练,集中式差分隐私训练,分布式联邦学习训练,DP应用在FL上训练;FL里又有两种分布IID和Non-IID。
工具包: Opacus
实验模型: BERT, RoBERTa, DistillBERT and ALBERT
数据集:推特Depression抑郁检测数据集、Sexual Harassment数据集(从推特爬取,作者的Github里有)
变量设置:隐私预算epsilon= 0.5, 5, 15, ∞
评估标准: accuracy+标准差
实验结果:
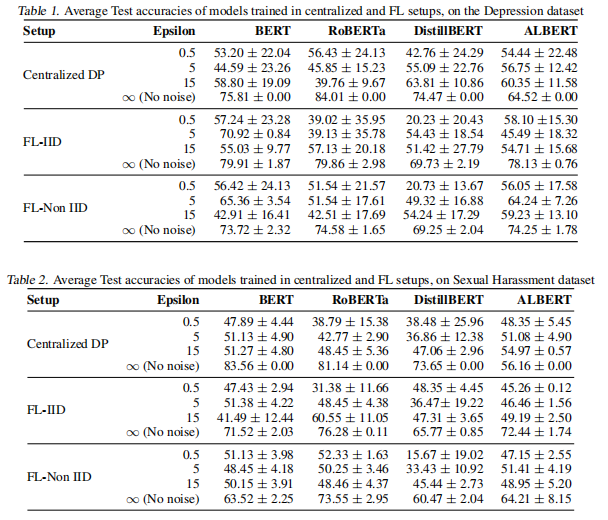
作者发现:
-
epsilon越大,标准差越小。
-
FL+DP,准确度会降,FL表现比DP更好。
结论:
(1)当采用DP训练时,较小的网络(如 ALBERT 和 DistillBERT)比较大的模型(如 BERT 和 RoBERTa)降级得更优雅(即DP训练时,小模型epsilon越大准确度越高,大模型epsilon越大准确率越低)(这里缺少数据可视化不太直观)
(2)在 FL 的 Non-IID 设置(医疗应用中的现实场景)中,效用退化平均高于 IID 设置(即准确率较之下降),这表明需要针对 Non-IID设置定制训练算法
(3)DP在训练数据量小的情况下比数据量大的情况下对效用的影响更不利。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!