Selenium+Scrapy 政策数据爬取方案流程
本文最后更新于:2021年5月9日 晚上
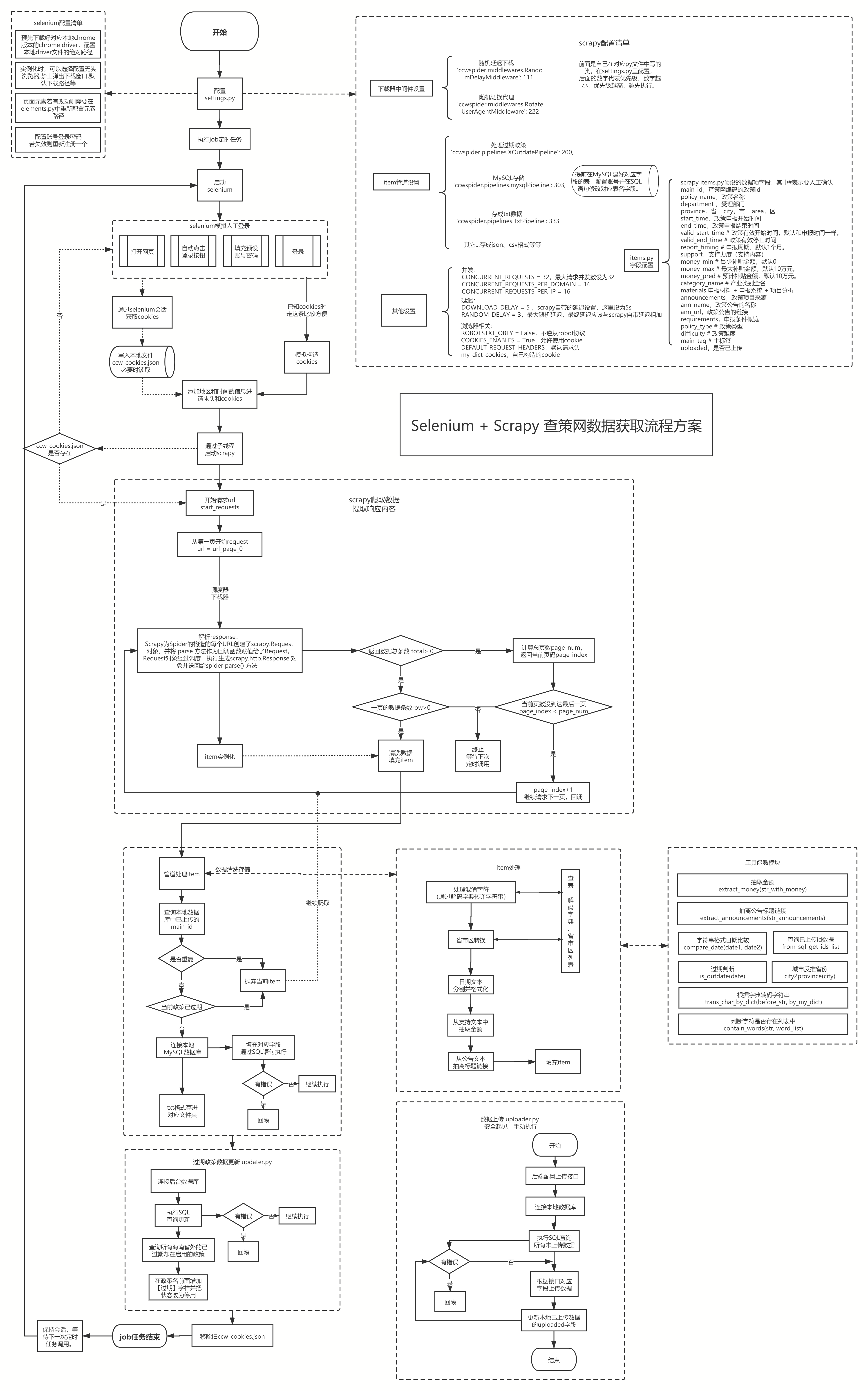
# 数据产品岗实习时画的数据获取方案流程图
目标网站是查策网,有很多人工整理手工上传的政策数据,一开始还好,破解一下加密json模拟一下cookie就行,后来反爬措施好像加强了,需要手填验证码,可以debug暂停填完然后继续。
代码在我的Github政策数据挖掘里,陆续上传代码。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!
本文最后更新于:2021年5月9日 晚上
# 数据产品岗实习时画的数据获取方案流程图
目标网站是查策网,有很多人工整理手工上传的政策数据,一开始还好,破解一下加密json模拟一下cookie就行,后来反爬措施好像加强了,需要手填验证码,可以debug暂停填完然后继续。
代码在我的Github政策数据挖掘里,陆续上传代码。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!
目录